* 본 포스팅은 이전 포스팅과 이어지는 내용입니다.
0. 개요
- 이전 포스팅에서 사용한 Player와 Team Entity를 동일하게 사용할 예정이다.
- 이전 포스팅에서 Fetch Join의 기본 개념과 ManyToOne 관계에서의 Fetch Join을 알아보았다.
- 이번 포스팅에서는 ManyToMany 관계 또는 Collection 필드의 Fetch Join을 알아보자.
1. Collection Fetch Join
- ManyToMany 관계 또는 Collection 필드를 JOIN 할 때에는 중복 데이터가 발생한다.
- 사실 DB의 관점에서는 중복 데이터는 존재하지 않는다.
- 그러나 JPA의 관점에서는 중복 객체가 발생한다.
- 어떤 문제가 있는지, 문제의 원인과 해결 방법이 무엇인지 알아보자.
a) 문제점 - 중복 결과 반환
- 각 Team에 몇 명의 선수가 등록되어 있는지를 확인하려고 한다.
- 이를 위해 다음과 같은 JPQL을 작성하여 실행하였다.
String query = "select t from Team t join fetch t.players";
List<Team> resultList = em.createQuery(query, Team.class).getResultList();
for (Team team : resultList) {
System.out.println("team = " + team + " || team name = " + team.getName() +
" || players = " + team.getPlayers().size());
}

- 위의 사진에서 볼 수 있듯이, 동일한 데이터가 출력되는 것을 확인할 수 있다.
- Fetch Join으로 N + 1 문제는 발생하지 않았으나, 중복된 객체를 반환하는 문제가 발생하였다.
- 왜 이런 중복 객체가 발생하는 것일까?
b) 중복 객체의 원인
- 우선 위에서 사용한 JPQL을 살펴보자.
SELECT t FROM Team t JOIN FETCH t.players;
- 이 JPQL은 다음과 같은 SQL로 번역되어 DB에게 전달된다.
SELECT t.*, p.* FROM Team t INNER JOIN Player p
ON t.id = p.team_id;
- 그렇다면 위의 SQL은 어떤 결과를 반환할까?
- 여기서 중요한 점은 INNER JOIN을 사용했다는 것이다. INNER JOIN은 매칭 되는 데이터를 반환한다.
- 그러므로 다음과 같은 결과를 출력하게 된다.
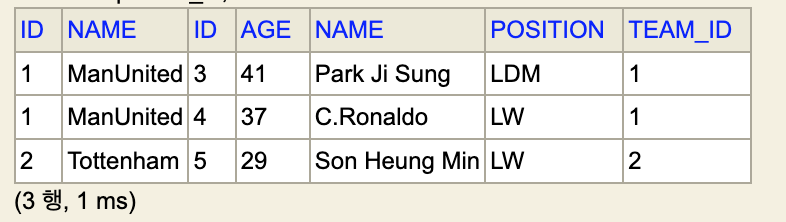
- 위의 사진은 DB의 조회 결과다.
- 이처럼 Team과 Player 테이블의 매칭 데이터를 반환하기 때문에, 중복 값이 발생하는 것이다.
- 그렇다면 간단하게 SQL의 DISTINCT 기능을 사용하여 제거하면 되지 않을까?
c) DISTINCT 기준의 차이
- 실제로 DISTINCT 키워드를 사용하여 다음과 같이 DB를 조회했다.
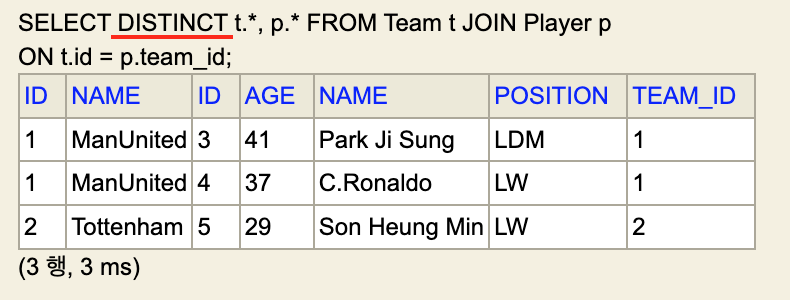
- 그러나 결과는 동일하다.
- 분명히 DISTINCT 키워드를 사용했는데, 중복이 제거되지 않았다. 왜 그럴까?
- 그 이유는 중복의 기준이 다르기 때문이다.
- RDB에서는 하나의 행이 하나의 데이터다. 즉, Row를 기준으로 중복을 검사한다.
- 위의 결과를 보면 ManUnited라는 값은 중복되지만, 그 외의 값은 중복되지 않는다.
- 즉, RDB의 입장에서 이 결과는 중복 데이터가 아니다.
- 그렇다면 중복의 기준을 객체로 설정할 수 있을까?
d) JPQL에서 제공하는 DISTINCT
- 이 문제는 JPQL에서 제공하는 DISTINCT 키워드를 사용하여 해결할 수 있다.
- JPQL에서 제공하는 DISTINCT는 다음 2가지 기능을 가진다.
→ JPQL 번역 시, SQL문에 DISTINCT 키워드를 추가
→ 객체의 중복을 제거
- JPQL에서 제공하는 DISTINCT는 다음의 과정을 거친다.
→ JPA는 JPQL을 번역하여 DISTINCT를 포함한 쿼리를 DB에게 전달한다.
→ JPA는 DB로부터 반환된 결과에서 중복된 객체(= 동일한 메모리 주소)를 가지는 데이터를 제거한다.
- 다음 예시를 통해서 알아보자.
SELECT DISTINCT t FROM Team t JOIN FETCH t.players
- 위의 JPQL에서 반환될 값은 Team 객체(= t)다.
- 그러므로 JPA는 DB로부터 반환된 결과에서 Team 객체의 값(= 메모리 주소)을 기준으로 중복을 제거한다.
- 아래의 코드를 실행하여 발행되는 쿼리와 반환되는 결과를 확인해보자.
String query = "select distinct t from Team t join fetch t.players";
List<Team> resultList = em.createQuery(query, Team.class).getResultList();
for (Team team : resultList) {
System.out.println("team = " + team + " || team name = " + team.getName() +
" || players = " + team.getPlayers().size());
}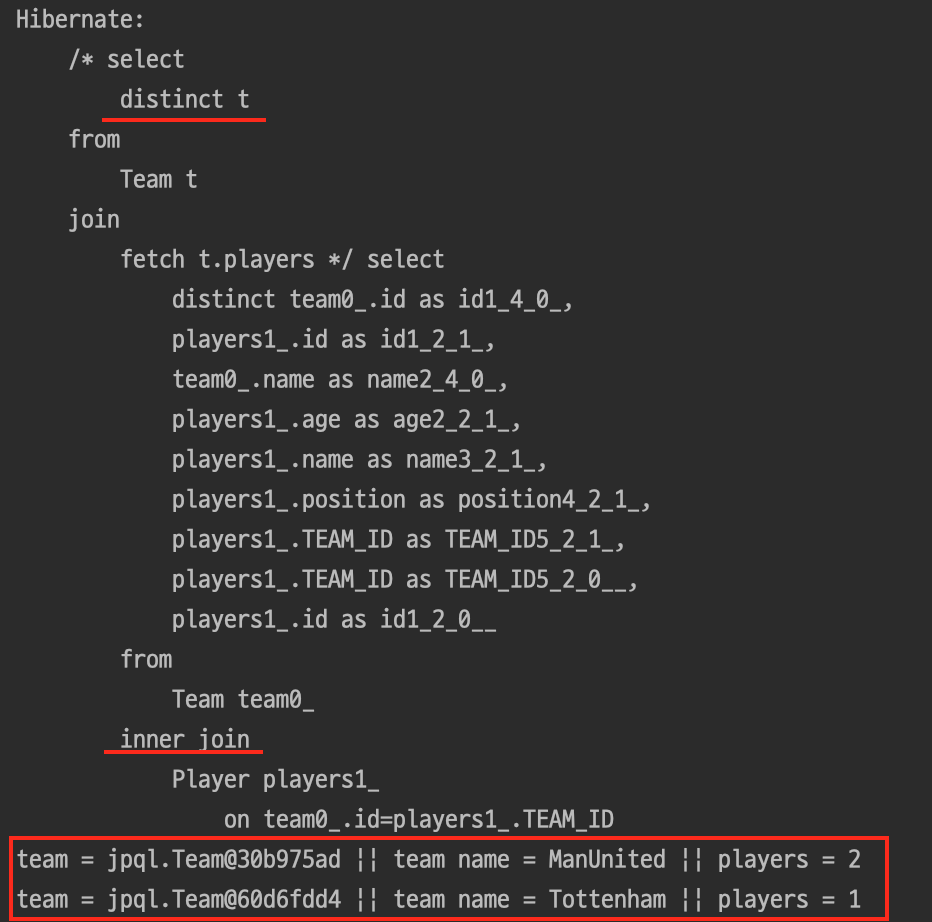
- 이처럼 중복 없는 결과를 반환하는 것을 확인할 수 있다.
a) 요약정리
- Fetch Join을 사용하여 ManyToMany 관계 또는 Collection 필드 조회 시, 중복 객체가 발생한다.
- 중복 객체를 제거하기 위해 JPQL에서 제공하는 DISTINCT 키워드를 함께 사용한다.
'Back-end > JPA 개념' 카테고리의 다른 글
| 34. JPQL - 다형성 쿼리, Entity 직접 사용, Named 쿼리 (0) | 2022.05.07 |
|---|---|
| 33. JPQL - Fetch Join의 한계 (0) | 2022.05.06 |
| 31. JPQL - Fetch Join 개념 (0) | 2022.05.04 |
| 30. JPQL - 경로 표현식과 묵시적 JOIN (0) | 2022.05.03 |
| 29. JPQL - 사용자 정의 함수 (0) | 2022.05.02 |




댓글