1. CSV 파일 만들기
- 구직사이트에서 받아온 데이터를 CSV(엑셀)파일의 형식으로 만들어보겠습니다.
- indeed에서 받아온 자료부터 만들어보겠습니다.
(1) save.py
- open이라는 함수는 파일을 읽거나 해당 파일이 존재하지 않을 시 생성하는 함수입니다. 이 함수를 이용해 파일을 생성합니다.


- 코드작성의 편의를 위해 잠시동안 스크래퍼 기능들을 주석처리합니다. save.py에 함수를 만들어준 뒤 main에서 실행을 하게 되면 job.csv라는 파일을 생성합니다.
(2) 행(column) 만들기

- indeed에서 받아온 정보는 title, company, location, link 이렇게 4가지 입니다. 이 4가지 종류의 데이터가 엑셀파일에서 행(column)의 역할을 하게 됩니다. 아래 사진을 참고해 주세요

- 위의 코드를 실행하면 아래의 사진처럼 job.csv파일에 첫번째 행이 완성됩니다.

(3) 크롤링한 데이터의 value만 받아오기
- 기존에 크롤링(스크래핑)한 정보들을 살펴보면 키와 값의 형태로 묶여져 있습니다. 아래 사진을 참고해주세요.

- 여기서 값(value)만 받아올 수 있도록 만들어보겠습니다.
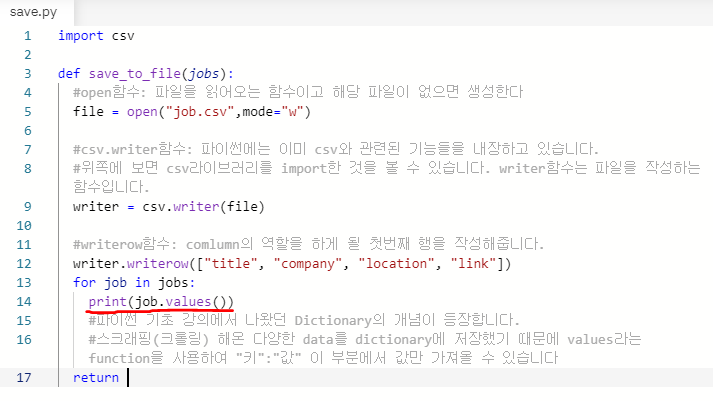
- 위의 코드를 기반으로 시험삼아 job.values()를 출력해보면 value부분만 깔끔하게 출력됩니다.

- dict_values라는 부분에서 볼 수 있듯이 dictionary에서 키를 제외한 값(value)만 출력됩니다. 하지만 dictionary는 엑셀파일을 만들기에 적합한 자료형은 아닙니다. 이것을 list로 형변환을 해줘야 합니다.


- 이제 리스트 형태로 바뀐 결과가 출력된다는 것을 확인할 수 있습니다. 이제 모든 준비가 끝났으니 job.csv파일에 이 데이터들을 작성해봅시다.
(4) 리스트 형태의 데이터를 job.csv에 작성하기
- 테스트를 위해 출력문을 작성했던 부분을 writer로 바꿔준 뒤에 실행을 합니다.
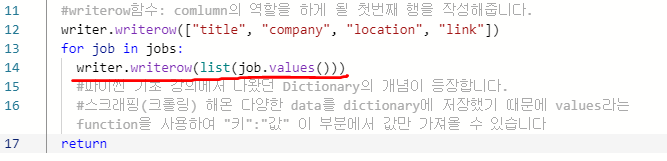
- 아무 이상없이 잘 작동한다면 job.csv파일로 들어가 결과를 확인합니다.

- 아주 잘 작동하니 주석처리를 해놓았던 stackoverflow 스크래핑 기능을 포함해서 job.csv에 작성해봅시다.
(5) 마무리
- 이제 마지막 작업입니다. 저와 동일하게 repl을 이용해 제작하셨다면 job.csv파일을 다운받으셔서 구글 엑셀에 들어가 import(가져오기) 작업을 진행하시면 됩니다. 저의 경우 엑셀을 이용하면 인코딩 형식이 달라서 한글이 깨지더라구요. IDE를 통해서 작업하셨다면 작업 폴더에 이미 해당 파일이 존재하겠죠?
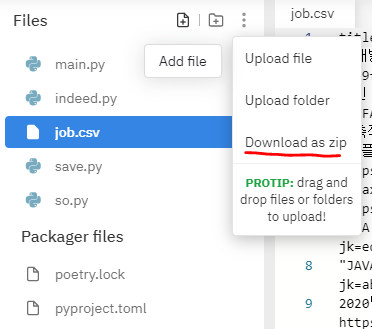

- 완성입니다.
- 만드신 기능을 가지고 유용하게 써보시면 좋겠습니다. 새로운 장난감이 하나 완성됐네요.
- 여기까지 제 글을 읽어주신 분들 감사합니다. 다른 포스팅으로 찾아뵙겠습니다.
'Back-end > Python Scrapper' 카테고리의 다른 글
| Flask로 웹스크래퍼 만들기 - 2 (0) | 2020.08.09 |
|---|---|
| Flask로 웹스크래퍼 만들기 - 1 (0) | 2020.08.09 |
| 파이썬으로 웹스크래퍼 만들기 - 5 (0) | 2020.08.05 |
| 파이썬으로 웹스크래퍼 만들기 - 4 (0) | 2020.08.04 |
| 파이썬으로 웹스크래퍼 만들기 - 3 (0) | 2020.08.03 |



댓글