1. 회사 이름 추출하기
- 앞선 포스팅에서 설명했던 동일한 방식으로 HTML의 구조를 분석하여 이번에는 회사의 이름을 추출해 보자.

- HTML을 분석해보면 이전에 이미 알고있는 div태그에 company라는 span에 String으로 회사 이름이 들어가 있는 것을 볼 수 있다. 하지만 가끔 몇몇 회사들은 a태그로 회사이름에 링크를 걸어놓는 경우가 있다. 우리는 이 두가지 경우 모두를 생각하여 코드를 만들어 보자. (if문을 사용한다.)

- 결과는 아래와 같이 잘 출력된다.

- 이 결과의 문제점은 결과간의 공백이 존재한다는 것이다. 이 공백을 없애주기 위해 우리는 strip() 함수를 사용할 수 있다.

- 결과는 아래와 같이 공백없이 깔끔하게 나오는 것을 확인할 수 있다.

2. 코드정리
- 지금까지 만든 코드를 조금 더 작은 단위로 나누어 정리해보자. 아래의 사진을 참고해주시기 바랍니다.

- title과 company를 각각 key와 value로 묶어 jobs라는 배열에 넣어주었다. 출력 결과는 아래와 같다.

- 이제 main으로 넘어가서 이 값들이 잘 출력되는지 확인해보자.
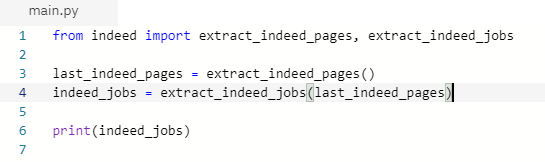

- 잘 출력된다.
3. 위치 추출하기
- 앞서 동일한 방식으로 HTML의 구조를 분석하여 위치를 추출하기 위한 코드를 만든다.

4. 상세 페이지 링크 추출하기
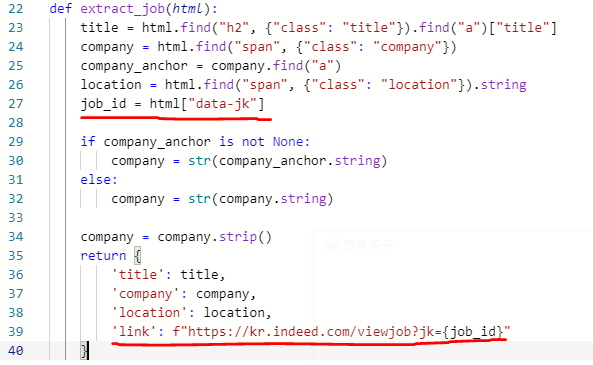
5. 최종 출력
- main으로 넘어가서 이제 모든것이 잘 작동하는지 확인해 봅시다.
- 아래에 제 코드를 적어 둘테니 필요하신 분들은 가져가세요.
<<<<<<<<<<<<<<<<<main.py>>>>>>>>>>>>>>>>>>
from indeed import extract_indeed_pages, extract_indeed_jobs
last_indeed_pages = extract_indeed_pages()
indeed_jobs = extract_indeed_jobs(last_indeed_pages)
print(indeed_jobs)
<<<<<<<<<<<<<<<<<indeed.py>>>>>>>>>>>>>>>>>
import requests
from bs4 import BeautifulSoup
LIMIT = 50
INDEED_URL = f"https://kr.indeed.com/jobs?q=java&l=%EC%84%9C%EC%9A%B8%ED%8A%B9%EB%B3%84%EC%8B%9C&jt=new_grad&limit={LIMIT}&radius=25"
def extract_indeed_pages():
result = requests.get(INDEED_URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("h2", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
location = html.find("span", {"class": "location"}).string
job_id = html["data-jk"]
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
return {
'title': title,
'company': company,
'location': location,
'link': f"https://kr.indeed.com/viewjob?jk={job_id}"
}
def extract_indeed_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping page {page}")
result = requests.get(f"{INDEED_URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
'Back-end > Python Scrapper' 카테고리의 다른 글
| 파이썬으로 웹스크래퍼 만들기 - 6 (0) | 2020.08.06 |
|---|---|
| 파이썬으로 웹스크래퍼 만들기 - 5 (0) | 2020.08.05 |
| 파이썬으로 웹스크래퍼 만들기 - 3 (0) | 2020.08.03 |
| 파이썬으로 웹스크래퍼 만들기 - 2 (0) | 2020.08.03 |
| 파이썬으로 웹스크래퍼 만들기 - 1 (0) | 2020.07.31 |



댓글