1. 사이트 주소(url) 알아내기
- indeed 사이트의 정보를 추출하는 웹 스크래퍼를 만들어 볼겁니다. 자신이 원하는 검색어로 검색을 한 뒤에 맞춤검색을 통해 페이지에 표시할 검색결과의 개수를 50개로 설정해 주세요. 이후 나온 검색결과의 url 주소를 복사해두시면 됩니다. 저는 서울특별시의 직장 중 java를 필요로하는 신입공채를 검색하였습니다.


2. Requests 라이브러리 설치하기
- 웹 스크래퍼를 만들기 위해서는 먼저 URL에 대한 요청을 처리할 수 있는 기능을 가진 라이브러리를 필요로 합니다. 그렇기에 Requests라는 라이브러리를 설치합니다.
(1) 왼쪽 메뉴바에서 패키지를 선택하고 request를 검색한 뒤에 첫번째 검색결과를 선택합니다.
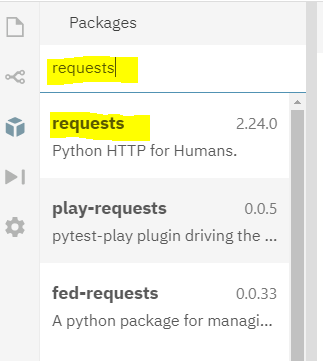
(2) 첫번째 검색결과를 선택 후 오른편에 보이는 + 모양을 클릭하면 자동으로 설치가 됩니다.
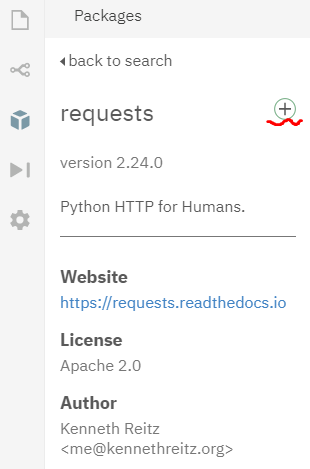
(3) 설치가 완료되면 오른쪽 커맨드/프롬프트에서 결과를 확인할 수 있습니다.

(4) requests 라이브러리를 사용하는 방법을 알아봅시다. 아래의 링크에 들어가보면 자세한 설명이 나와있습니다.
https://requests.readthedocs.io/en/master/
Requests: HTTP for Humans™ — Requests 2.24.0 documentation
Requests: HTTP for Humans™ Release v2.24.0. (Installation) Requests is an elegant and simple HTTP library for Python, built for human beings. Behold, the power of Requests: >>> r = requests.get('https://api.github.com/user', auth=('user', 'pass')) >>> r.
requests.readthedocs.io
3. Requests를 이용하여 결과값 받아오기
(1) requests의 get메소드를 이용하여 링크에서 받아올 수 있는 검색 결과의 개수를 확인해 봅니다.
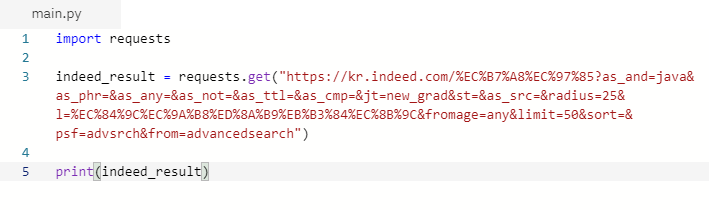
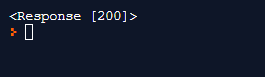
(2) 위의 사진처럼 잘 작동한 것을 확인했으면 이제 text(html)를 받아와 봅시다.
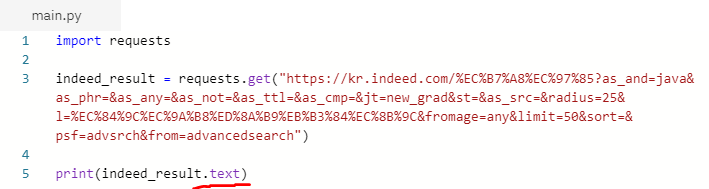
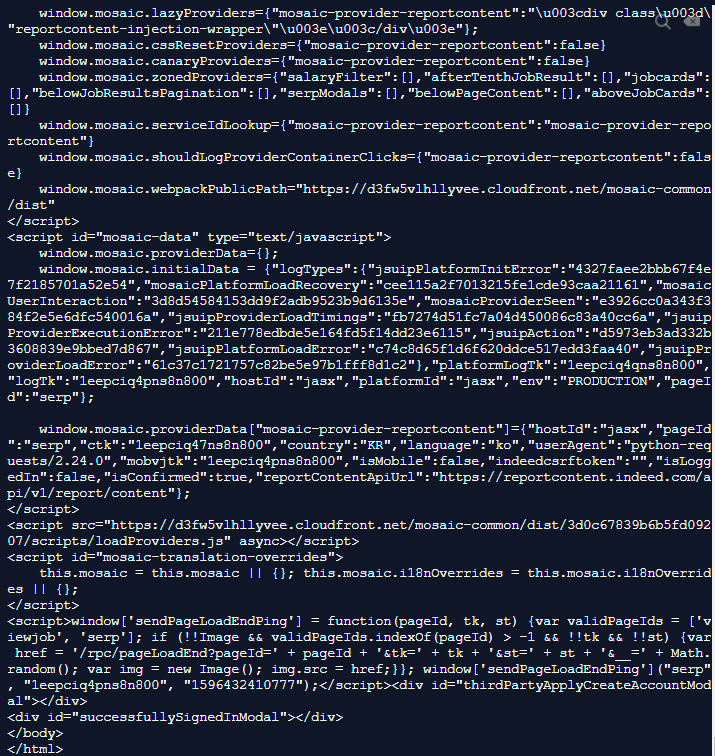
- 검색결과를 출력한 페이지에서 엄청난 양의 html을 받아온 것을 확인할 수 있습니다. 이제 이것을 기반으로 원하는 정보만을 추출해봅시다.
4. BeautifulSoup4 라이브러리 설치하기
(1) 위에서 볼 수 있듯이 text(html)을 기반으로 원하는 정보를 추출하기 위해 수작업을 하는 것은 매우 힘듭니다. 이를 편리하게 할 수 있도록 우리는 beautifulsoup4 라는 라이브러리를 사용해 봅시다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call unicode() or str() on a BeautifulSoup object, or a Tag within it: str(soup) # ' I linked to example.com ' unicode(soup.a) # u' I linked to example.com ' The str() functio
www.crummy.com
(2) 앞서 requests 라이브러리를 설치한 방법과 동일하게 beautifulsoup4 라이브러리의 설치를 완료합니다.
5. Beautifulsoup 사용하기
- beautifulsoup 라이브러리는 쉽게 말해 데이터를 추출하는 역할을 합니다. 다시 말해, soup이란 html에서 원하는 데이터를 추출하기 위한 수단입니다. 아래 링크의 문서에 들어가면 어떻게 사용하고 시작할 수 있는지 나와 있습니다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#quick-start
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call unicode() or str() on a BeautifulSoup object, or a Tag within it: str(soup) # ' I linked to example.com ' unicode(soup.a) # u' I linked to example.com ' The str() functio
www.crummy.com
(1) Quick start
- beautifulsoup 라이브러리를 import합니다
- indeed 검색결과 페이지의 url을 이용하여 받아온 html을 beautifulsoup을 이용하여 parse합니다. (여기서 parse한다라는 것은 beautifulsoup 라이브러리가 이해할 수 있는 형식의 html로 변환/번역 해준다고 생각하면 됩니다.)
- beautifulsoup이 변환된 html을 잘 이해하고 작동시키는지 결과를 출력해봅니다.
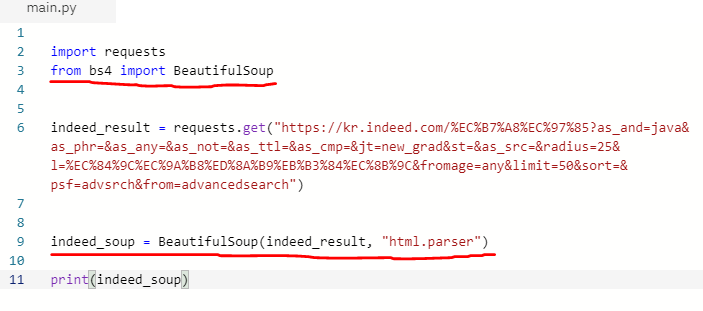
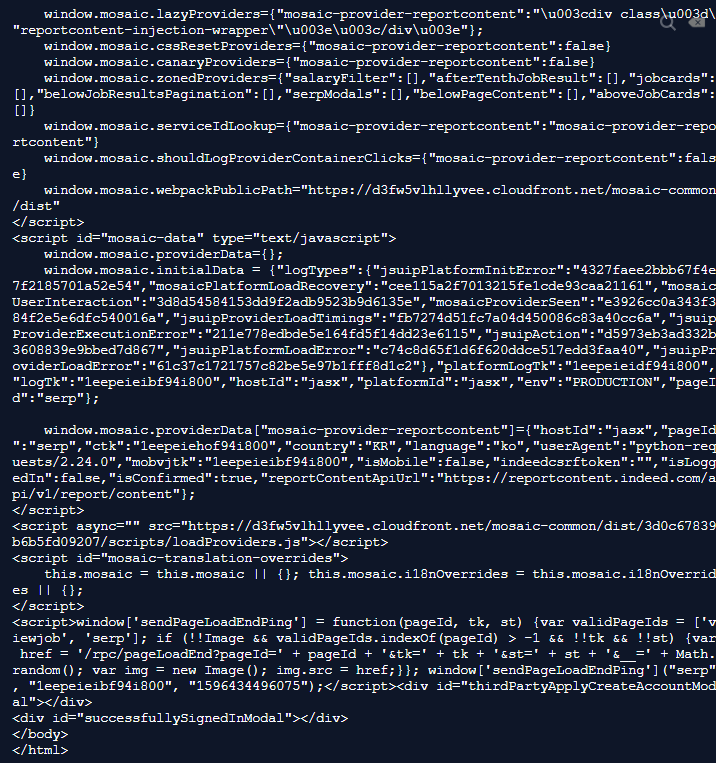
- 위의 코드를 실행하면 또 엄청난 양의 html이 출력되는 것을 볼 수 있습니다.
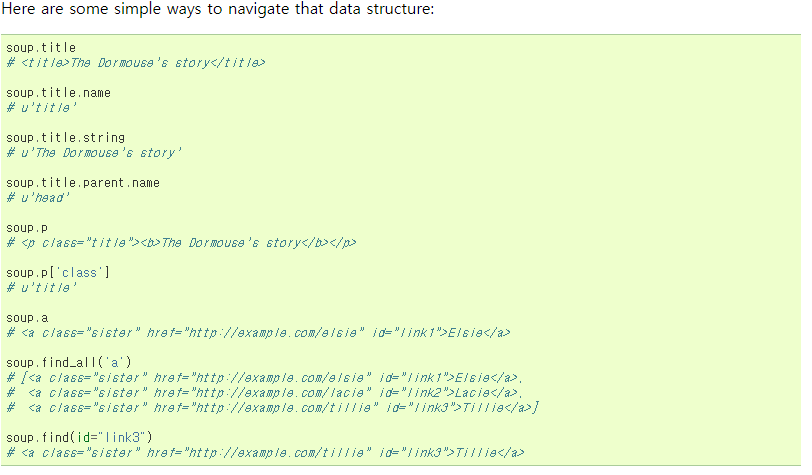
(2) 위에 제가 링크를 걸어둔 beautifulsoup문서를 읽어보시면 기본적인 html 태그에 대한 이해가 있으신 분들은 아래와 같이 간단하게 html 구조에 따라 필요한 태그를 찾는 다양한 방법이 있다는 것을 알 수 있습니다.
(3) 페이지 처리 부분 찾아보기
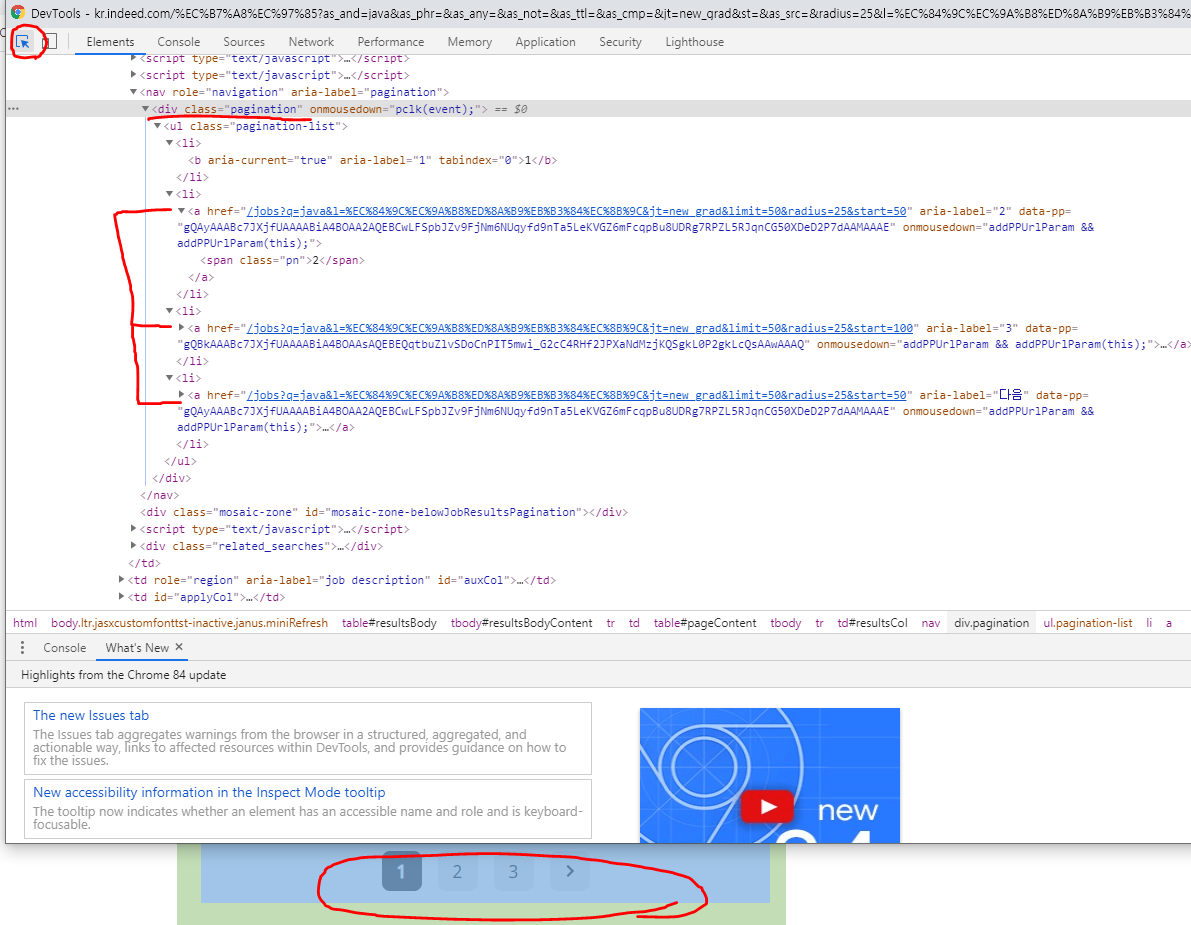
- indeed 검색결과 창에서 크롬을 이용해 개발도구(F12)를 들어가시면 페이지 처리 부분을 확인해 볼 수 있습니다.
- 페이지 처리 부분인 pagination에 링크가 걸려있는 것을 아래 사진과 같이 찾아보세요. (저는 페이지가 3개뿐이라서 링크가 3개만 걸려 있습니다.)
(4) 페이지 처리부분인 pagination을 확인해보면 div태그에 pagination이라는 클래스 명을 사용한다는 것을 확인할 수 있습니다. 이를 이용해 beautifulsoup에서 해당 태그를 찾을 수 있도록 코드를 짭니다.
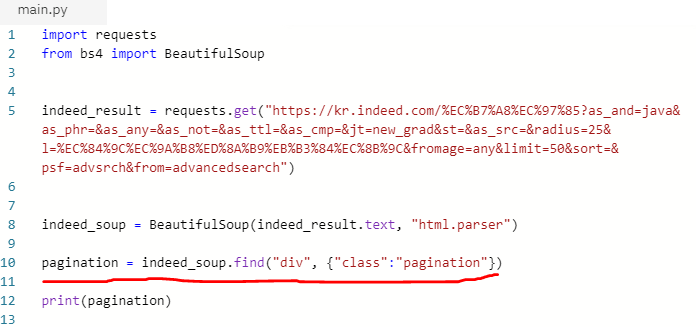
- 빨간색 밑줄친 부분을 보시면 beautifulsoup 라이브러리에 있는 find라는 함수를 사용해 div를 찾고 class의 이름이 pagination이라는 부분을 찾으라는 코드입니다. 이것을 출력하면 아래와 같이 나옵니다.
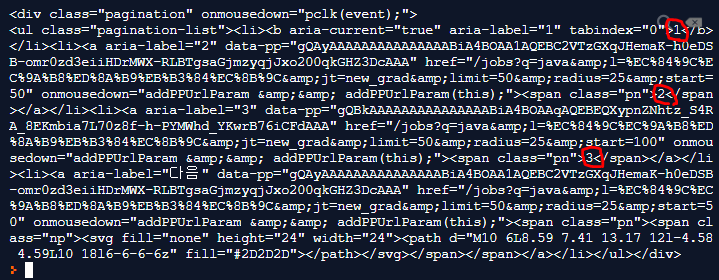
- 빨간색 원 부분이 우리가 사이트에서 보면 페이지 처리가 되어있는 부분입니다. 저는 검색결과가 3페이지만 존재하기 때문에 위의 사진에서 볼 수 있듯이 1,2,3 페이지가 있는것을 찾아볼 수 있습니다. 데이터의 범위는 줄어들었지만 아직 우리가 원하는 정확한 페이징처리 정보는 추출하지 못했습니다. 그 부분을 해봅시다.
(5) 개발자 도구를 이용해 indeed의 검색결과 페이지 구조를 다시 보면 pagination이라는 이름의 div태그 아래에 a태그가 있고 그 아래에 다시 span태그가 있는 것을 볼 수 있습니다.

이제 pagination에서 a태그(anchor)와 그 아래의 페이지 번호(1,2,3)이 적혀있는 span을 추출해 봅시다. 여기서 주의할 점은 위의 사진에서 보시다 시피 a태그와 span태그는 li태그(리스트)에 의해 감싸져 있습니다. 그러므로 리스트 안에는 여러개의 태그가 존재하겠죠? 반복문인 for문을 이용하여 span을 추출해 봅시다.
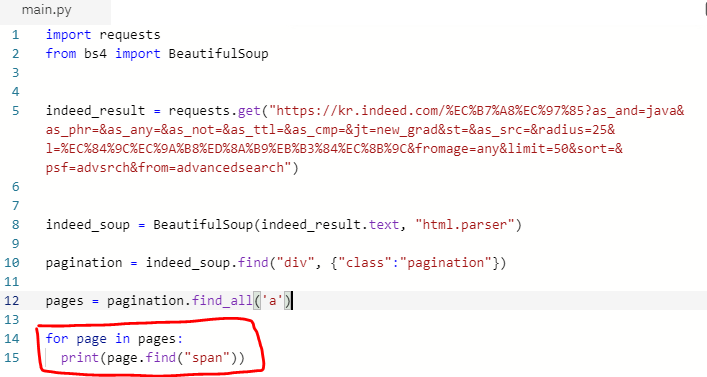

- 1번 페이지 번호가 나오지 않은 이유는 현재 우리가 보고 있는 검색결과 페이지가 1번 페이지이기 때문입니다.
- 마지막 줄에 나온 알 수 없는 코드들은 '다음' 페이지를 나타내기 위함인데, 저의 경우 검색 결과 페이지가 3개 뿐이기 때문에 다음 페이지로 넘기는 일은 없겠죠? 그것을 나타낸 코드입니다. 그렇다면 이 마지막 코드를 없애봅시다.
(6) 먼저 우리가 추출한 데이터를 배열에 저장합니다. 그 후에 마지막에 저장된 필요없는 정보를 없애주면 됩니다.
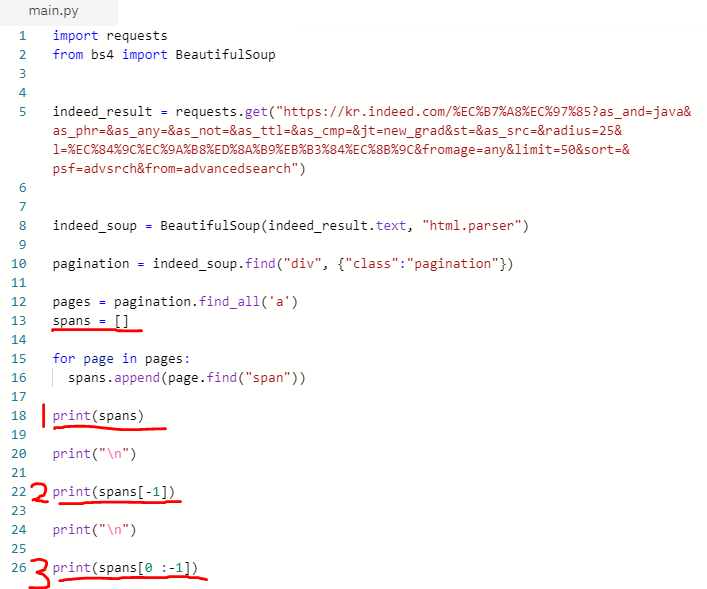
- spans라는 이름의 배열을 선언하고 append를 이용하여 for문을 통해 우리가 찾았던 pagination의 span정보를 담아줍니다.

- 필요없는 마지막 정보가 어디에 있는지 확인합니다. 1번의 결과를 보면 배열의 맨 마지막에 있는걸 확인할 수 있습니다.
- spans 배열에는 3개의 정보가 들어있습니다. 배열은 0번부터 시작하니 당연히 마지막 자료는 2번 이겠죠? 하지만 반대로 생각해보면 마지막 배열의 요소는 0보다 하나 작은 -1이 될수도 있습니다. 그래서 제가 print(spans[-1])이라고 출력을 한것입니다.
그 결과가 2번입니다.
- 다른 방식으로 print(spans[0:-1])의 경우에는 배열의 자리번호(index)가 0번부터 -1번 이전까지 출력하라는 의미입니다. 그러므로 -1번째 자리의 배열 요소는 출력되지 않습니다. 그 결과가 3번입니다. 추가로, 0을 생략하고 print(spans[:-1]) 이렇게 작성해도 결과는 동일합니다.
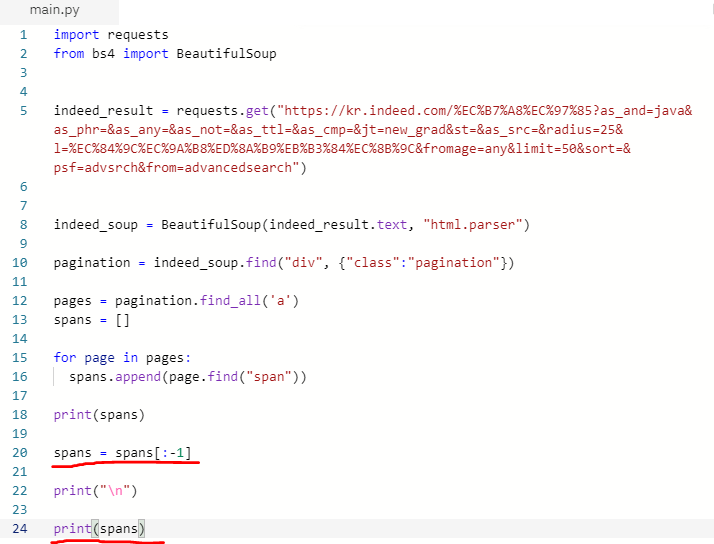
- 자 이제 간단한 방법을 통해 마지막 배열요소를 없애줍시다.

'Back-end > Python Scrapper' 카테고리의 다른 글
| 파이썬으로 웹스크래퍼 만들기 - 6 (0) | 2020.08.06 |
|---|---|
| 파이썬으로 웹스크래퍼 만들기 - 5 (0) | 2020.08.05 |
| 파이썬으로 웹스크래퍼 만들기 - 4 (0) | 2020.08.04 |
| 파이썬으로 웹스크래퍼 만들기 - 3 (0) | 2020.08.03 |
| 파이썬으로 웹스크래퍼 만들기 - 1 (0) | 2020.07.31 |


댓글