1. pages에서 String만 추출하기
(1) 지난 시간에 우리는 배열에 span부분을 저장했습니다. 그렇다면 span에 있는 String만 찾아서 저장해봅시다.


(2) 하지만 우리가 진행했던 위의 코드는 효율성이 좋지 않은 코드입니다. a태그인 anchor를 찾고 그 안의 span을 찾고 span에 있는 string을 추출해 내는 방식이기 때문입니다. HTML의 구조를 잘 안다면 이런 과정을 생략하고 한번에 string을 찾을 수 있다는 것을 알게됩니다. anchor에서 String을 바로 찾아내는 방법이죠.

(3) 어떻게 이렇게 쉽게 찾을 수 있을까요? 크롬의 개발자 도구를 이용하여 HTML의 구조를 파악해 봅시다.
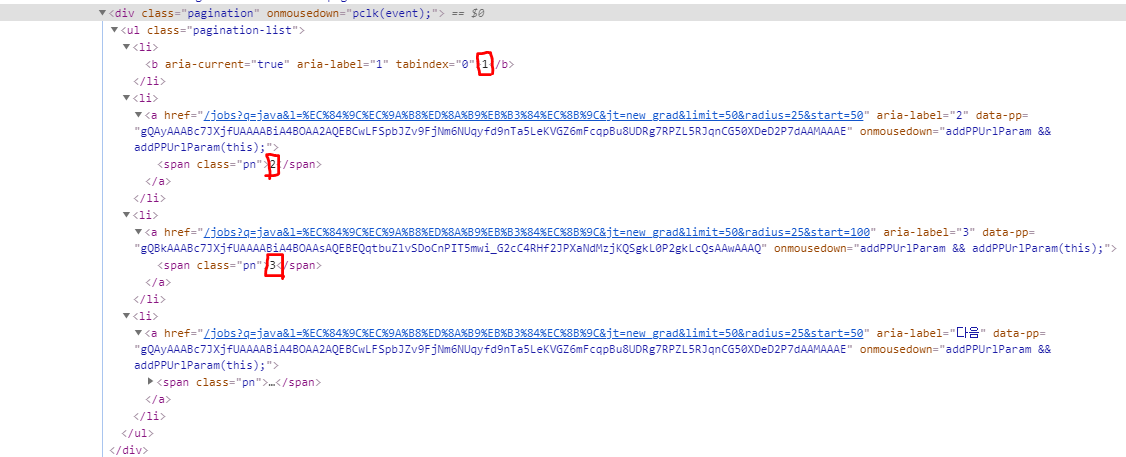
(4) 위의 사진에서 알 수 있듯이 a태그 아래에 존재하는 String은 페이지 번호를 나타내는 숫자가 유일하기 때문입니다. 그렇다면 이제 이 String을 우리가 사용할 수 있도록 정수형으로 바꿔줍시다.


(5)문자형 요소를 담고있는 배열이 아닌 정수형 요소를 담고있는 배열이 출력되는 것을 볼 수 있습니다. 이제 배열 내부의 가장 큰 숫자를 찾아 max_page라는 변수에 담아봅시다.


2. 최대 페이지 수 만큼 request 보내기
(1) 페이지 수를 이용해서 request를 페이지 수 만큼 만들어 보겠습니다. 지금 저의 예시에서는 3페이지 밖에 없기때문에 직접 request를 3번 만들면 간단한 일이지만 만약 추후에 페이지가 100개라면 어떻게 해야 할까요?
- 이런 문제를 간단히 해결하기 위해서 range라는 함수를 이용해 볼겁니다. range함수는 0부터 입력한 특정 수까지 또는 지정한 수의 범위를 이용하는 함수입니다. 아래의 예시를 봅시다.


- max_page 변수는 현재 최대 페이지 수인 3을 갖고 있습니다. range함수를 적용했더니 0부터 3까지 라고 출력이 됩니다. 이렇게 range함수는 범위를 설정하는 함수입니다.
- 여기서 가장 중요한 점은 range함수를 사용하면 0부터 시작한다는 것입니다. 그러므로 실제로 수행하게 되는 범위는 0,1,2까지라는 것 입니다.
(2) indeed 싸이트의 검색결과 페이지에서 2번째, 3번째 페이지로 이동했을때 url이 어떻게 변하는지 살펴볼까요?


- 이처럼 두번째 페이지는 start=50, 세번째 페이지는 start=100이라고 표시됩니다. 이건 무슨 뜻일까요? 화면에 출력되는 검색결과들은 한 페이지당 50개씩 출력이 되도록 설정해 놓았습니다. 각 구직정보가 0번 부터 번호가 매겨진다면 첫번째 페이지에서는 0번에서 49번까지 출력이 되겠죠? 그렇다면 두번째 페이지는 50번부터, 세번째 페이지는 100번부터 시작되겠죠? 그 의미입니다. 이것을 이용해 봅시다.


- 이렇게 문자열을 만들어 놓는다면 웹사이트 스크래핑을 위해 페이지를 변경해야 할때, 이 문자열들을 이용할 수 있습니다.
3. 코드정리
(1) 현재 시점에서 지저분하게 써내려간 코드들을 정리해 봅시다. 우리가 페이지를 추출했던 부분을 하나의 모듈로써 function으로 만들어 깔끔하게 만들어 봅시다. (*function을 만들때는 들여쓰기를 꼭 잊지말고 해주세요!)

(2) main으로 돌아가서 잘 작동되는지 확인해 봅시다.


(3) 페이지 수 만큼 request를 만드는 function도 만들어 봅시다. 위에서 만들었던 url의 start부분과 limit 부분을 자동으로 바꿔주는 코드를 짜줍니다.
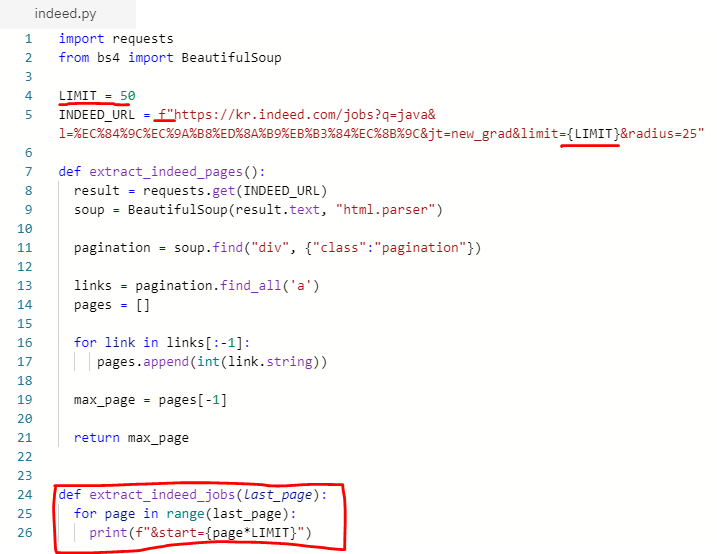
(4) main으로 이동해서 방금 만든 코드의 작동을 확인합니다.


(5) 잘 작동하는 것을 확인했으니 이제 이걸 자동화 할 수 있도록 만들어 봅시다.

- status_code를 사용하여 자동화된 코드가 잘 작동되는지 확인해 볼 수 있도록 테스트합니다. 페이지가 3개이니까 작동 시 출력창에 200이 세번 출력되면 잘 작동된다는 의미입니다.

4. Job Title 추출하기
(1) 페이지 처리까지 완료했으니 이제 다음 작업을 진행해 봅시다. 지금 만들려고 하는것은 각 페이지에 들어가 구직 정보를 어딘가에 저장해서 출력할 수 있도록 하는 것인데, 그렇다면 저장할 수 있는 공간이 필요하겠죠? 같이 만들어 봅시다.
- 먼저 Job Title이 어디에 있는지 개발자 도구를 통해 살펴 봅시다
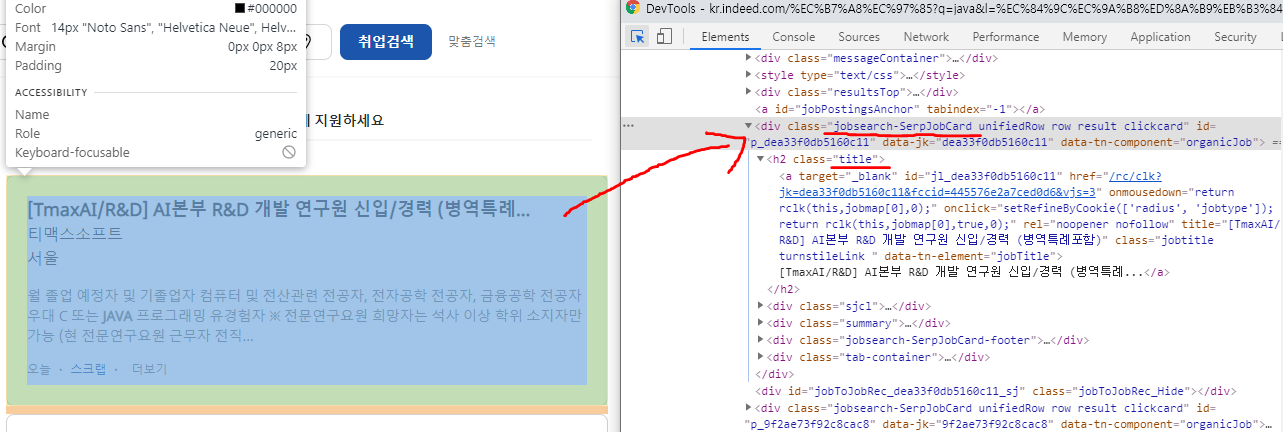
- 위의 사진에서 보면 알 수 있듯이 div태그에 jobsearch-SerpJobCard라는 이름의 class를 갖고 있고 그 아래에 title이라는 h2태그가 있는것을 확인할 수 있습니다. 이것을 기반으로 한번 만들어 봅시다.


- 결과 또한 아주 잘 나오는것을 볼 수 있습니다. 현재 작업중인 페이지가 3페이지 분량이라서 처리량이 얼마 안되지만, 페이지가 20페이지 이상이신 분들은 for문을 #(주석)처리 하시고 page*LIMIT 부분을 0*LIMIT으로 바꾸시고 테스트 하시기 바랍니다. 아래의 사진을 참고해주세요.

(2) 페이지 처리부분을 한 방식처럼 이번에도 이 soup에서 원하는 데이터(job title)를 추출해 봅시다.


- 위의 사진처럼, 검색결과 페이지의 HTML을 분석해보면 어떤 데이터는 String을 갖고 있지만 어떤 자료는 String을 갖고 있지 않은 경우가 있다. 하지만 모든 데이터의 공통점이 있다. a태그의 title이라는 속성에는 job title 정보를 갖고 있다는 것이다. 이것을 이용하자.
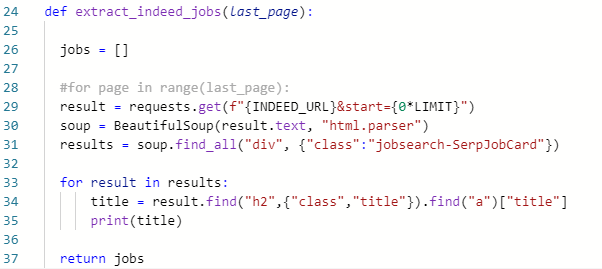
- div태그 중 jobsearch-SerpJobCard라는 class명을 갖고있는 부분을 찾아 soup으로 만들고 이걸 results라는 변수에 저장한다.
- 여러 정보를 담고있는 results를 for문을 이용해 title이라는 클래스명을 갖고 있는 h2태그 아래에 존재하는 a태그의 title 속성정보를 찾아오는 과정을 위의 코드로 만든 것이다. 결과는 아래와 같이 나온다. (*한 페이지당 50개의 결과가 나와야 한다!)

- 여기까지 Job title 출력을 완료했다. 다음에는 회사 이름을 추출하는 코드를 만들어보자.
'Back-end > Python Scrapper' 카테고리의 다른 글
| 파이썬으로 웹스크래퍼 만들기 - 6 (0) | 2020.08.06 |
|---|---|
| 파이썬으로 웹스크래퍼 만들기 - 5 (0) | 2020.08.05 |
| 파이썬으로 웹스크래퍼 만들기 - 4 (0) | 2020.08.04 |
| 파이썬으로 웹스크래퍼 만들기 - 2 (0) | 2020.08.03 |
| 파이썬으로 웹스크래퍼 만들기 - 1 (0) | 2020.07.31 |


댓글